"DDoSing" EKS & GKE to Study DR for My MSc Dissertation

I know what you're thinking—no, I didn't actually DDoS Amazon EKS and Google GKE. But, hear me out. It all started in 2022 during my MSc journey at Edinburgh Napier University, seeking a meaningful dissertation topic. Being intrigued by cloud technologies, their reliability, and the emerging world of Kubernetes that I already knew for years, I stumbled upon one crucially overlooked, yet fascinating area: disaster recovery (DR) of Kubernetes in the Cloud.
Disaster recovery is an often misunderstood area in cloud computing—many businesses assume that simply deploying applications to giants like AWS, Azure, or GCP ensures instant resilience against disasters. “It's in the cloud, it must be safe,” right? Wrong! Major outages have repeatedly proven that assumption false. These interruptions taught us decisions matter, especially in DR planning.
"But, Cloud Is Already Disaster Recovery!"
There's a dangerous assumption making the rounds these days—that deploying workloads in cloud services like AWS, Azure or GCP or other hyperscalers inherently guarantees disaster recovery. Contrary to popular belief, cloud services don't automatically immunize your application from disruptions. For my dissertation, I investigated and discussed precisely this false sense of security. Business continuity in the cloud isn't passively assured—it needs active, structured, and tested disaster recovery approaches.
Cloud environments provide robust foundations, yes—but DR and Business Continuity require intentional, proactive, and tested strategies. In December 2021, everyone still remembers AWS’s "day of reckoning" (Dec 7 & 10). That outage impacted dozens of high-profile services ranging from Netflix, to Amazon’s own Prime Now services, creating a ripple effect felt globally. It lasted hours and severely impacted business operations worldwide. And guess what? Similar outages have hit Azure and GCP as well over the years. The consequences? Lost data, increased downtime, customer dissatisfaction, and potentially catastrophic financial impacts.
Diving into Kubernetes and Disaster Recovery
My project, now publicly available here, aimed to leverage Kubernetes (the reigning champion for container orchestration) to measure the effectiveness and practicality of cloud-based disaster recovery strategies—specifically comparing Amazon Elastic Kubernetes Service (EKS) and Google Kubernetes Engine (GKE). While Kubernetes inherently provides some resiliency (automated recovery, scaling, resource balancing) and the Cloud too, it does not fully protect against DR scenarios, such as zonal/regional outages, misconfigurations, or failed updates.
In my project, titled "Disaster Recovery Analysis of Different Cloud Managed Kubernetes Clusters," the spotlight was pointed at two primary disaster scenarios based on common real-world events:
- Software Update Issues: Mishandled software updates frequently cause application outages. They're underestimated, yet brutally efficient killers of uptime, triggering real-life system failures countless times.
- Cloud Zonal Outages: A problem that impacts data centres or regions, shutting down a service entirely—a situation not really so uncommon among significant cloud providers.
My Methodology
To measure effectiveness, I employed Velero—an industry-leading tool built specifically for Kubernetes backup and recovery procedures. Velero not only simplifies backup and restoration tasks but also seamlessly integrates with various cloud providers (including AWS and GCP).
I defined two key performance metrics based on industry standard SLAs/SLOs:
- Recovery Point Objective (RPO): The maximum acceptable amount of data loss measured by time. Essentially, how much data can you afford to lose?
- Recovery Time Objective (RTO): The time constraints under which a business process must be restored after a disaster. In plain English—how long can your business afford to be offline?
I created practical scenarios and evaluated their RTO and partially RPO. The aim was simple—to objectively compare the resilience of Amazon EKS and Google GKE, uncover their hidden flaws, and genuinely understand cloud DR effectiveness.
The Technical Stack
Infrastructure management and automation formed the backbone for reproducible, practical scenarios:
- Terraform was crucial as infrastructure-as-code (IaC): allowing me to provision identical Kubernetes clusters repeatedly across AWS/GCP. Terraform modules were used to strictly define node pools, storage bucket layouts, Velero deployments, and related networking resources. Terraform enabled quick re-creation of my DR scenarios multiple times, oscillating effortlessly between AWS and GCP test environments.
- Helm served as my deployment orchestra: Deploying Kubernetes-managed applications and essential add-ons reliably. With Helm charts, I could quickly rollout the test applications, running repeatable, measurable experiments within minutes.
- Kustomize took this a step further—managing environment-specific configurations over Helm templates. Creating slightly modified versions of core infrastructure or workloads for different scenarios was remarkably efficient. Kustomize eliminated redundant configurations and facilitated cleaner DR scenario replicability.
- Bash scripting handled the glue for automation orchestration: each major DR test scenario ran through sequential operations (e.g., Create -> Deploy -> Backup -> Simulate DR -> Restore -> Validate), managed entirely through my bash scripts. With these scripts, DR tests became instantly repeatable, scalable, and auditable.
Beyond these key tools, the broader software stack supporting my research included version control and collaborative capabilities of Git and GitHub. Extensive data analysis and statistical representation were performed using R, visualizing key metrics clearly related to recovery times and resource performance. Additionally, cloud-native tools (AWS CLI and gcloud CLI) and Kubernetes-specific utilities (kubectl) were critical. Together, this integrated toolset created an efficient environment that deeply enhanced my ability to reliably simulate, automate, and analyze sophisticated disaster recovery scenarios.
Findings: Who Performed Better — EKS or GKE?
I discovered something interesting:
- Scenario 1 (Software Updates): After 50 tests on each cloud in the same timeframe, and alternatively, EKS showed a noticeably shorter RTO compared to GKE. This means that in case of application upgrade issues, or any other kind of application issue involving data, AWS’s EKS was faster at bouncing back, ensuring less downtime for critical workloads.
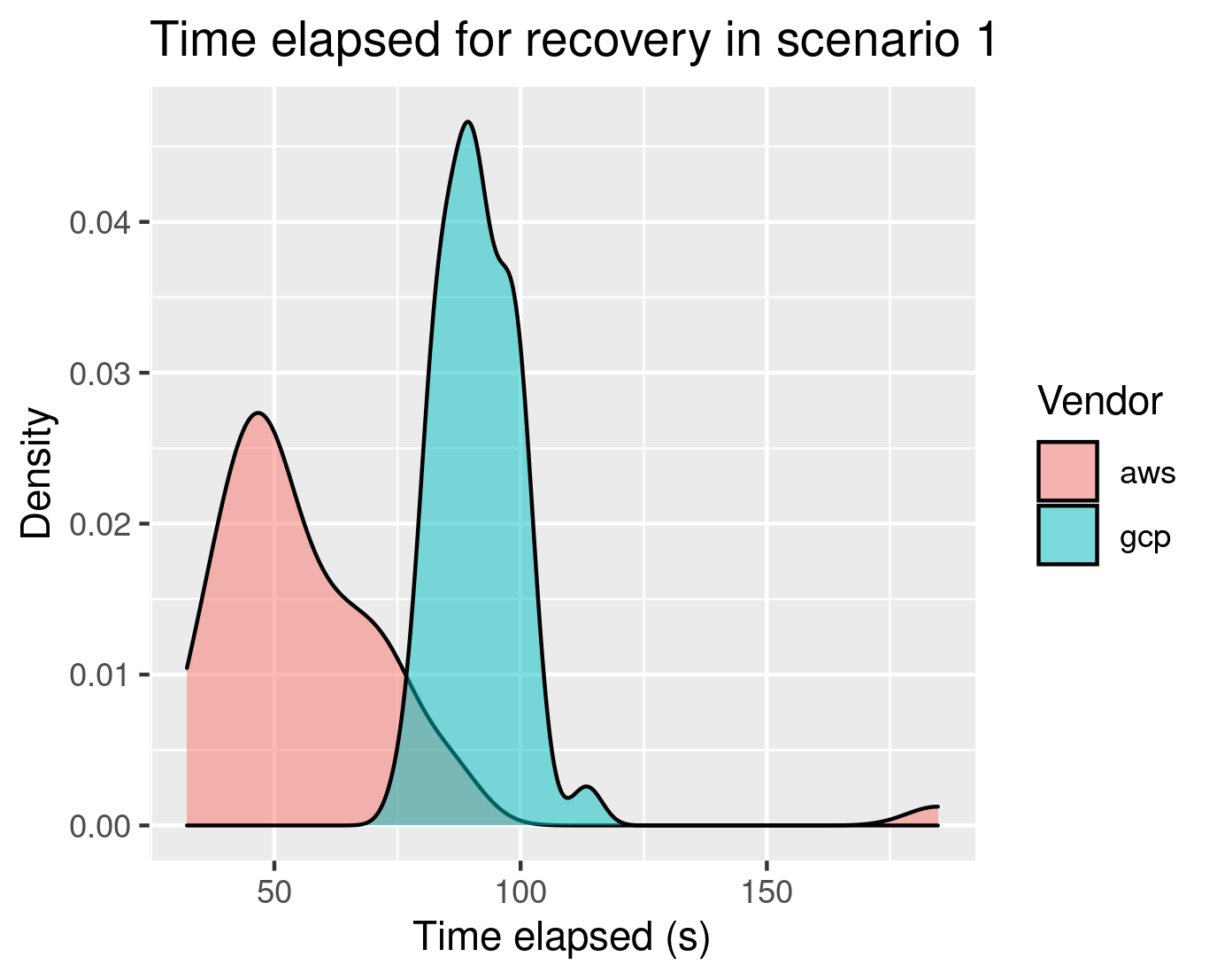
- Scenario 2 (Zonal Cloud Outage): After 20 tests on each cloud in the same timeframe, and alternatively, GKE vastly outperformed EKS. AWS's increased RTO was partly due to additional complexity introduced by the AWS-specific implementation of Cloud Identity (OpenID Connect provider, or OIDC), which took longer to reconcile after an incident.

Still, when leaving out this critical component (the OIDC), GKE was superior:
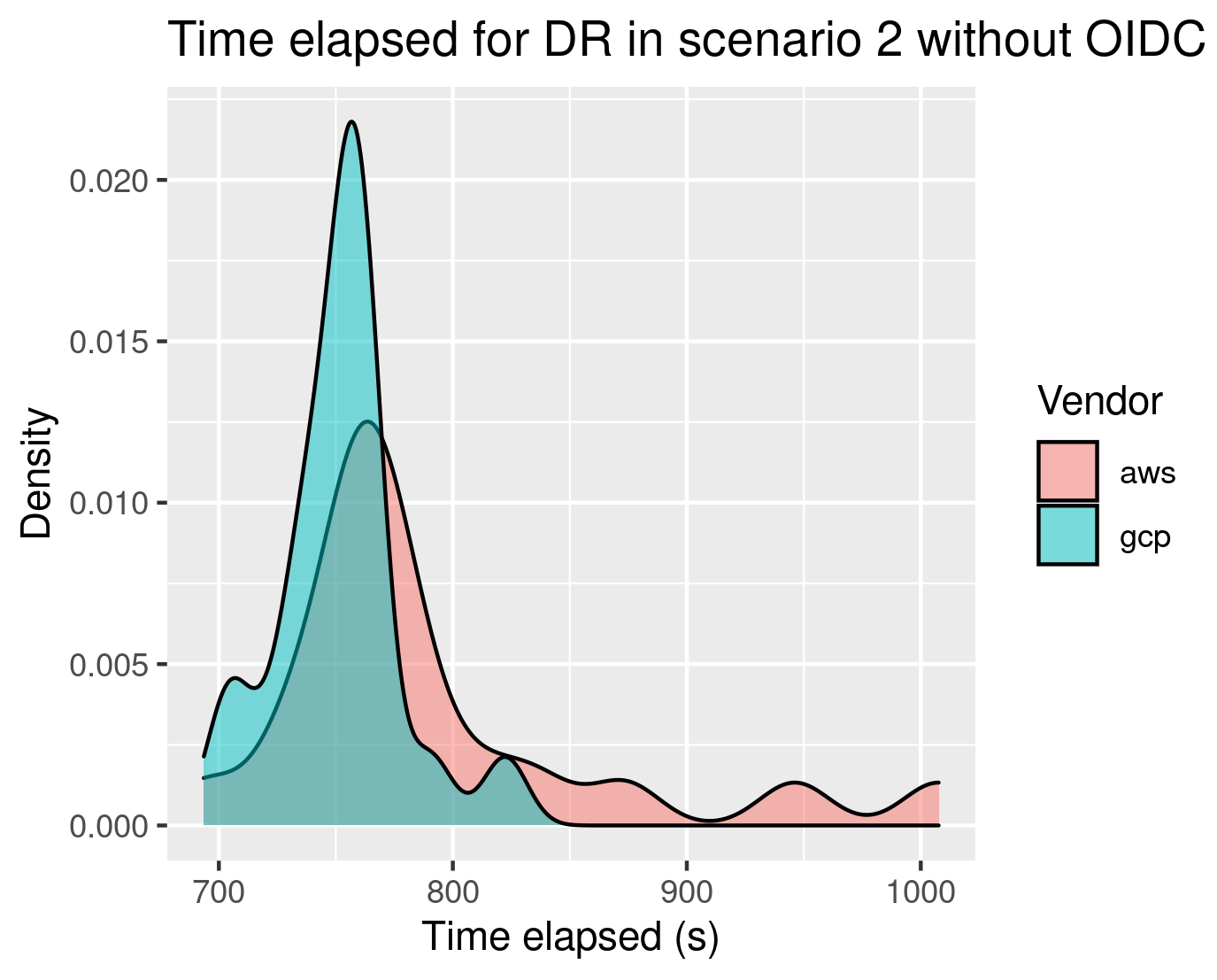
These outcomes highlight crucial takeaways:
- Google and Amazon each on its own have its advantages and disadvantages in terms of RTO, depending on the scenario.
- Even small configuration nuances—such as authentication mechanisms—can deeply impact the speed of recovery.
- Kubernetes clusters aren't magically robust against outages; their managed implementations have unique strengths and weaknesses.
In the end, the cost of all these tests didn't surpass 200€, which is somewhat expensive, but not that much after forcibly reducing the number of tests.
So, Do You Have a Real Disaster Recovery Plan?
You may have designed redundant systems and picked the best SLAs offered by cloud providers (99.95%, 99.99% uptime—sounds terrific, doesn’t it?), but that's only part of the equation. Your disaster recovery strategy is incomplete if you never test it, just accumulating dust in a forgotten wiki page.
To put it bluntly—DR strategies are worthless without testing. In fact, repeatedly testing your DR plans may actually save your business when the next cloud-wide outage strikes.
Another challenging reality I faced: DR Planning usually isn't triggered naturally at an engineer or developer level. It takes considerable effort, communication, resources, and management approval. Individual engineers typically have too much immediate work, making strategic DR preparation a management priority—a top-down initiative needed to ensure it gets proper attention and effort. Disaster recovery cannot practically remain just a side-project for busy engineers. It's fundamentally strategic, organizational, and must be championed by management.
Lessons Learned and Recommendations for Your Business
Through my MSc dissertation, I uncovered valuable insights:
- Businesses fully prepared and rehearsed for cloud disasters successfully minimize downtime and data loss. They survive and thrive.
- Always define clear, measurable RTO/RPO targets to tailor your DR plan to actual business needs.
- Understand your cloud provider's SLA/SLO guarantees and align them to your workload recovery objectives.
- Document meticulously: Record procedures, issues, improvements to enable clear workflows and troubleshooting in actual disaster events. Extensive documentation proved crucial to reproduce scenarios and debug performance rapidly.
- Incorporate tools like Velero or Kanister into your Kubernetes governance—reliable, industry-backed solutions fundamentally ease implementation and testing.
- Consider running Chaos Engineering with LitmusChaos, or ChaosMonkey, to induce controlled chaos into your clusters, and to force personnel to build and deploy resilient software.
- Businesses need to make disaster recovery planning tools like Velero routine, shifting from being reactionary ("after we lose data") to proactive.
- Let DR become management-driven mandate: Executives must elevate disaster recovery planning from engineering afterthoughts to strategic corporate priority—allocating resources and ensuring accountability.
In a world increasingly built on cloud technology, reliability against outage becomes critical—especially to brand trust, financial health, and market competitiveness. Cloud DR must occupy its rightful place at the forefront of business strategy and IT operation goals.
So, did I actually DDoS EKS and GKE? Thankfully, the digital world doesn't need my help with harmful incidents—it already has its share of disasters. Instead, I learned, analyzed, tested, and hopefully contributed my small part to keeping these disaster scenarios actionable rather than catastrophic.
Perhaps it's time to reflect—how's your disaster recovery readiness shaping up these days? If recent memory teaches us anything, it’s that the question isn't "if" another incident will happen; it’s simply "when?" And businesses prepared for disaster won't just survive—they will thrive.



